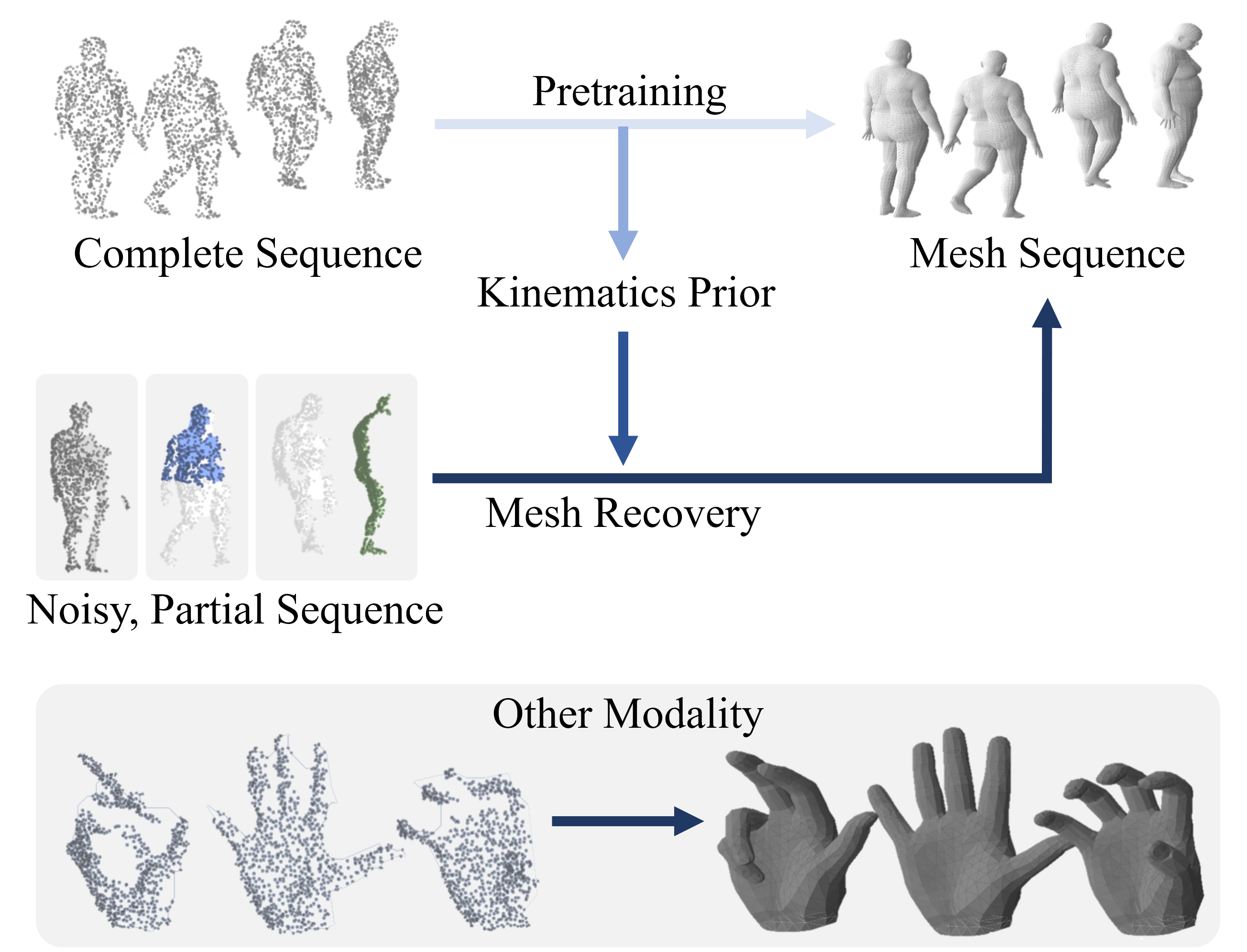
The exact 3D dynamics of the human body provides crucial evidence to analyze the consequences of the physical interaction between the body and the environment, which can eventually assist everyday activities in a wide range of applications. However, optimizing for 3D configurations from image observation requires a significant amount of computation, whereas real-world 3D measurements often suffer from noisy observation or complex occlusion. We resolve the challenge by learning a latent distribution representing strong temporal priors. We use a conditional variational autoencoder (CVAE) architecture with a transformer to train the motion priors with a large-scale motion dataset. Then our feature follower effectively aligns the feature spaces of noisy, partial observation with the necessary input for pre-trained motion priors, and quickly recovers a complete mesh sequence of motion. We demonstrate that the transformer-based autoencoder can collect necessary spatio-temporal correlations robust to various adversaries, such as missing temporal frames, or noisy observation under severe occlusion. Our framework is general and can be applied to recover the full 3D dynamics of other subjects with parametric representations.
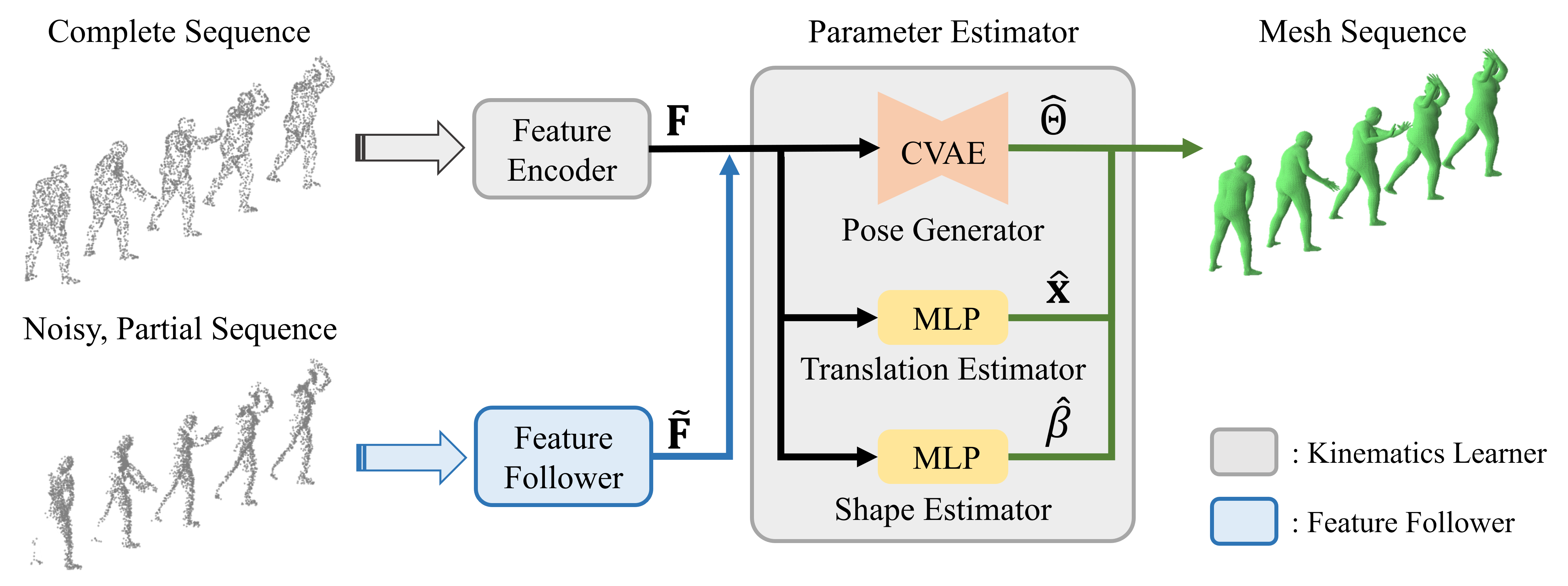
The Kinematics Learner, the point cloud feature encoder followed by the parameter estimator, learns how to recover mesh from the complete point cloud sequence input. The Feature Follower then follows the encoding of the feature encoder in the kinematics learner. The learning of the feature encoding makes our model to effectively handle noisy, partial point cloud sequence inputs.
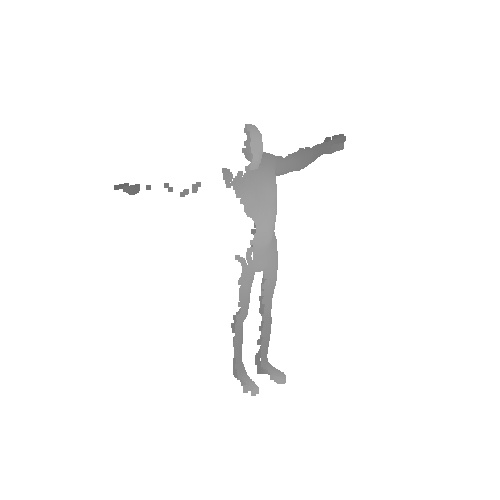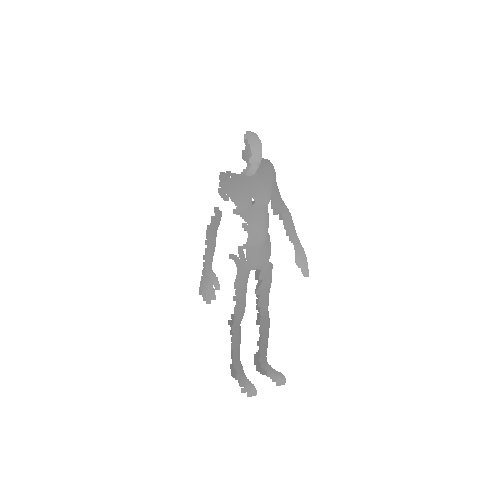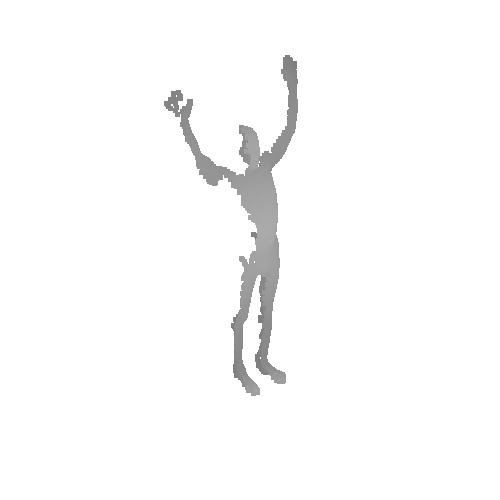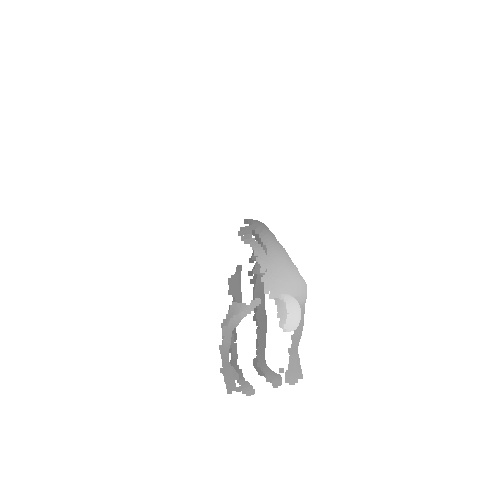 |
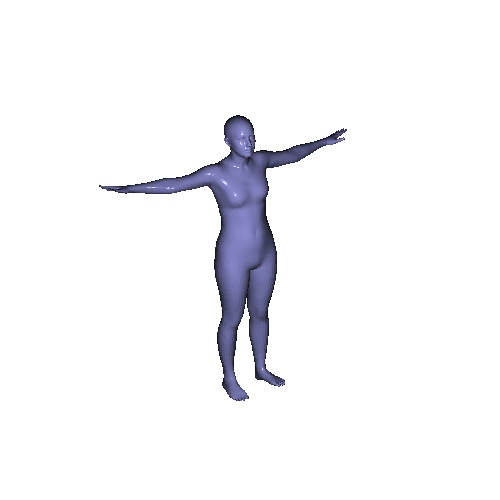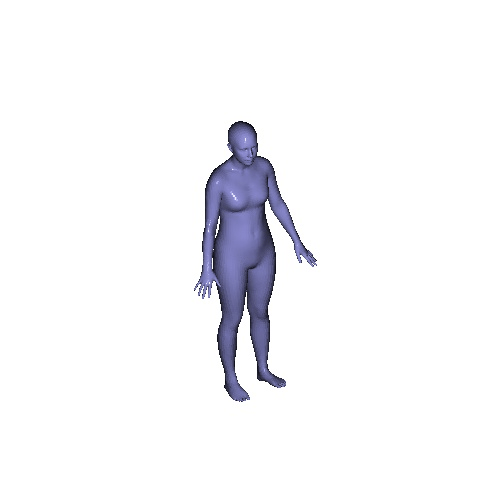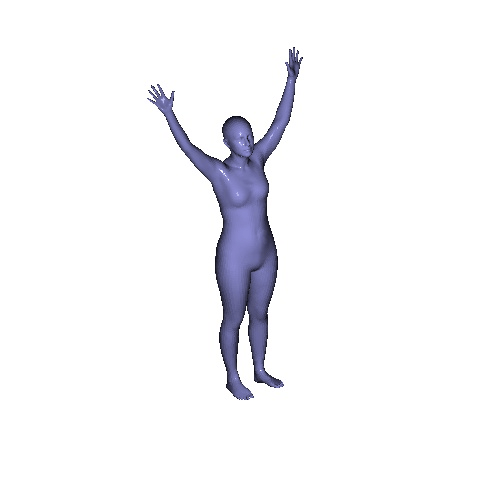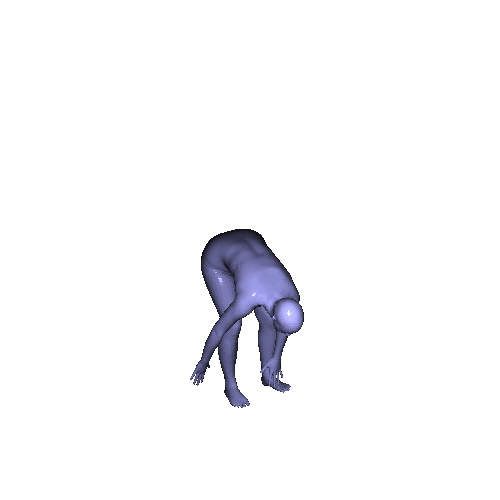 |
 |
 |
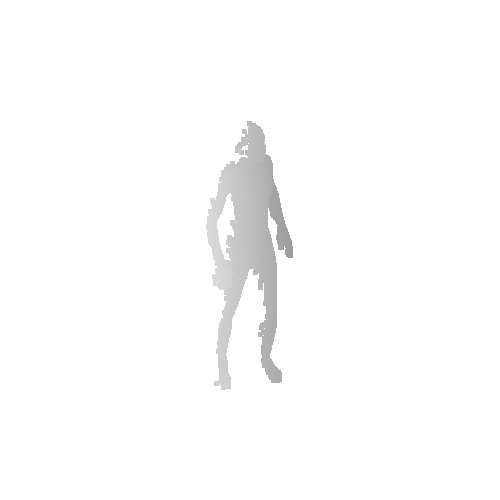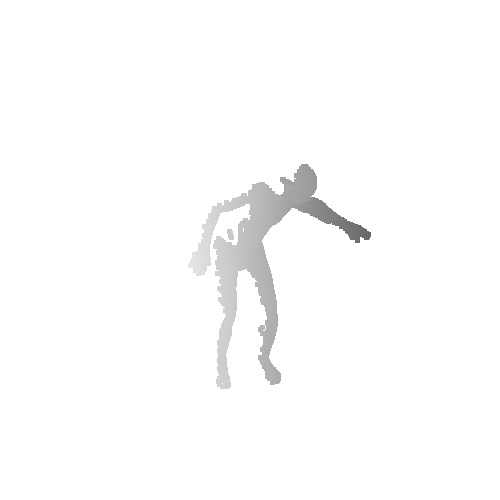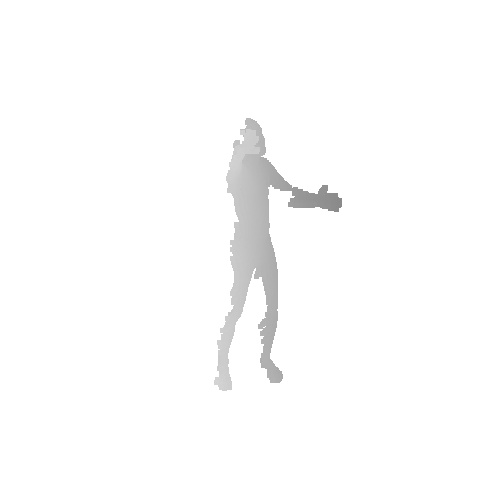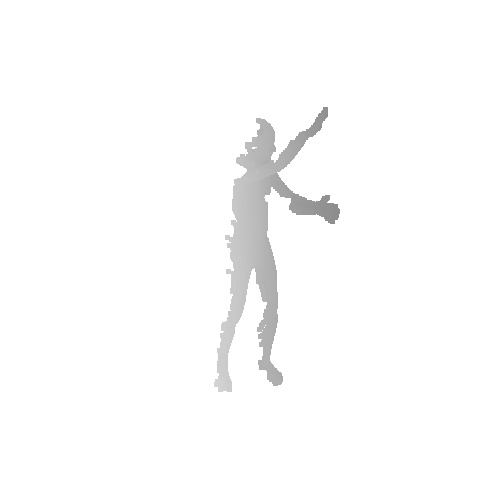 |
 |
 |
 |
| Input | Ours | VoteHMR | Zuo et al. |
|---|
Qualitative results on SURREAL dataset which is a synthetic human motion dataset. Baselines estimate the parameters for individual frames of input, and result in unnatural jittering motion within the sequence. On the other hand, our method correctly captures temporal correlation and reconstruct meshes with smooth motion.
 |
 |
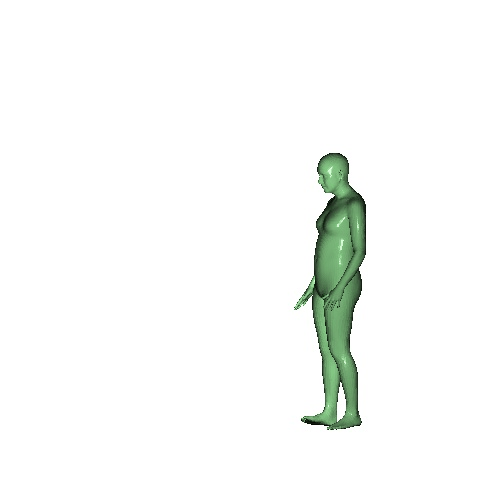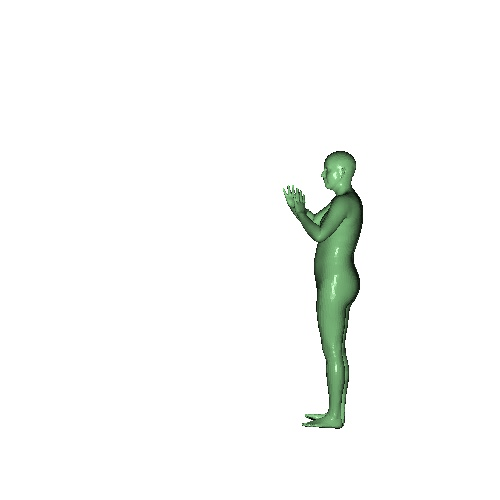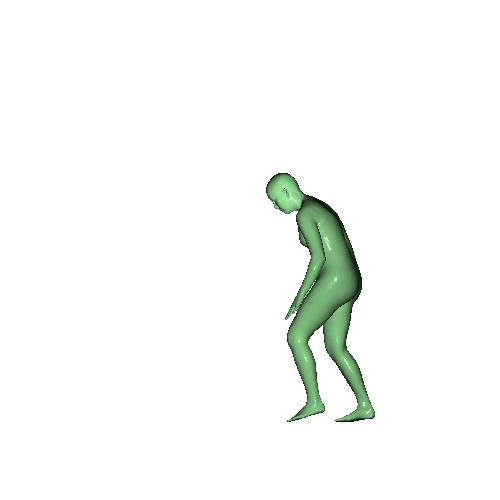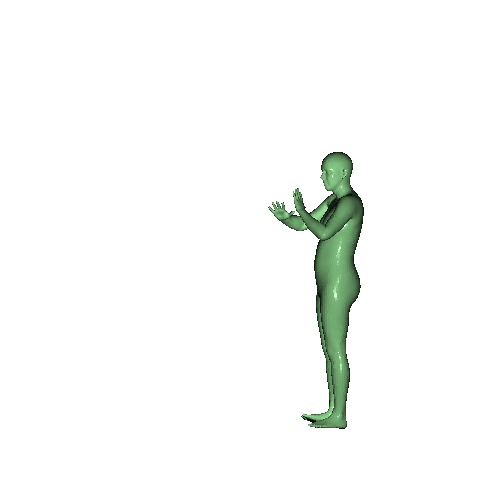 |
 |
 |
 |
 |
 |
| Input | Ours | VoteHMR | Zuo et al. |
|---|
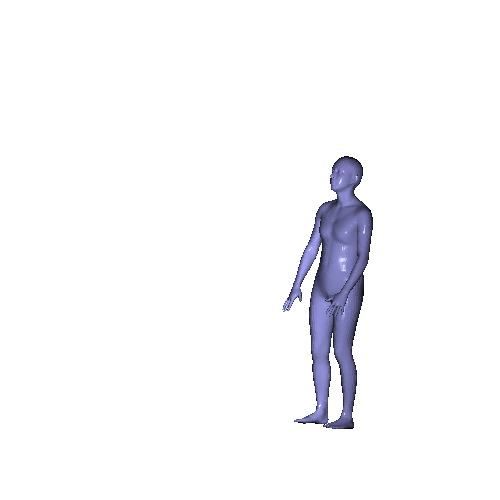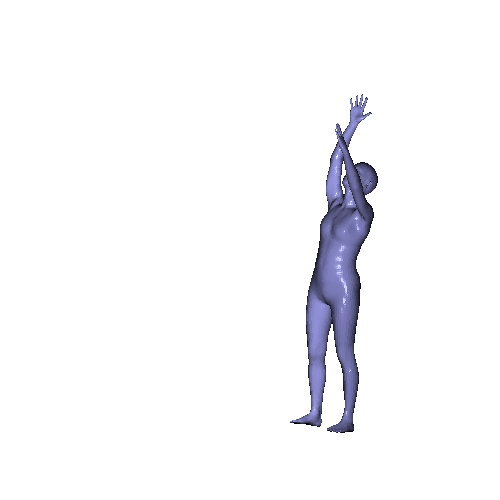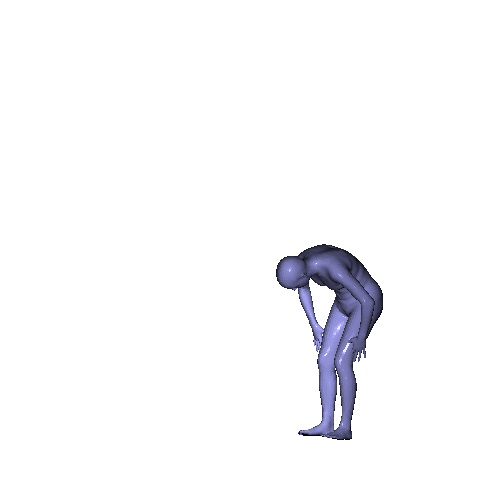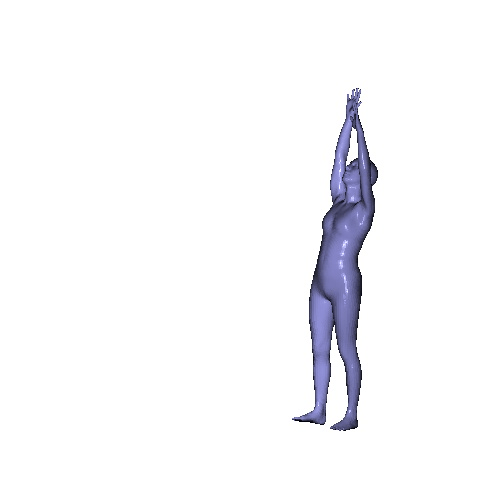
Qualitative results on Berkeley MHAD dataset which is a real human motion dataset. Even though the input point cloud is extremely noisy and the network is not fine-tuned to the noisy real data, our model recovers the mesh sequence.
 |
 |
 |
 |
 |
 |
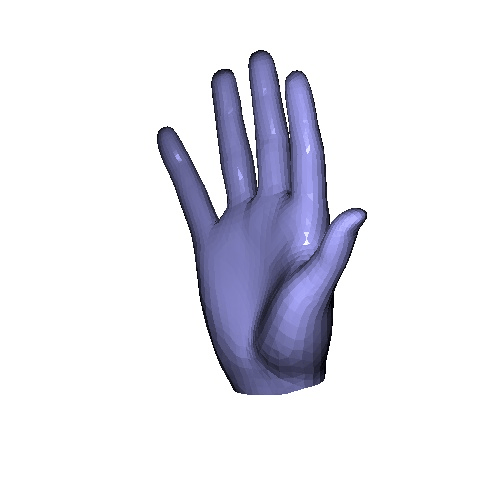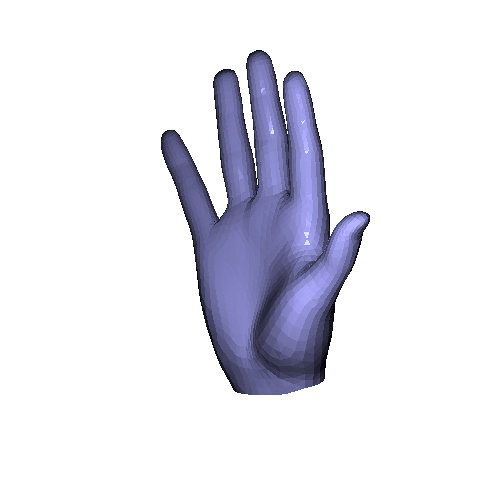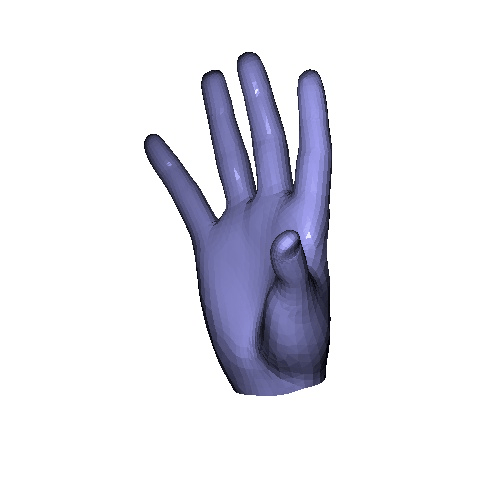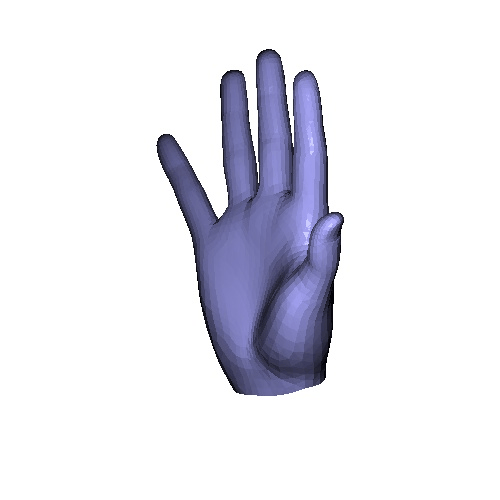 |
 |
| Input | GT | Ours | VoteHMR-M |
|---|
Qualitative results on InterHand2.6M & HanCo dataset. VoteHMR-M is our modification of VoteHMR to fit the MANO hand model. In the paper, we include quantitative analysis that our method achieves better result.
@InProceedings{Jang_2023_ICCV,
author = {Jang, Hojun and Kim, Minkwan and Bae, Jinseok and Kim, Young Min},
title = {Dynamic Mesh Recovery from Partial Point Cloud Sequence},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {15074-15084}
}
